Vector Search and Slides
VECTOR SEARCH | ||
|
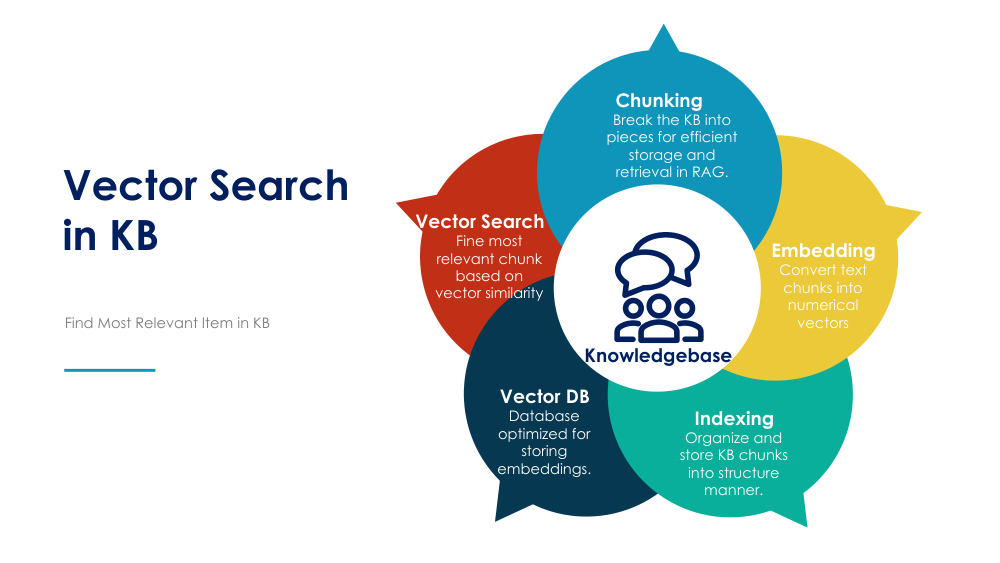
A detailed article on vector search and its application in knowledge bases with unstructured data, such as text, images, and other formats, would cover the following core concepts: Introduction to Vector SearchVector search is a method used to find the most relevant data in a knowledge base by representing data in vector (numerical) form and using similarity calculations. Unlike traditional keyword-based search, vector search retrieves data by comparing the underlying meanings or features rather than exact matches, making it ideal for handling unstructured data like text, images, and audio. With the surge in unstructured data in knowledge bases, vector search allows for more effective data retrieval by leveraging machine learning models to generate vector embeddings that represent the semantics of data, allowing more nuanced and contextually accurate search results. How Vector Search WorksThe main steps to implement vector search for a knowledge base containing unstructured data include:
Detailed Steps to Prepare the Vector Database and Build Vector Search
Challenges and Best Practices
ConclusionVector search for knowledge bases transforms how unstructured data is handled, offering meaningful search capabilities beyond exact keyword matching. Through vector embeddings, efficient indexing, and similarity-based querying, vector search can unlock significant value in knowledge bases containing diverse, unstructured data types, making it a powerful tool for modern information retrieval. |
Vector-databases-compared-ai-