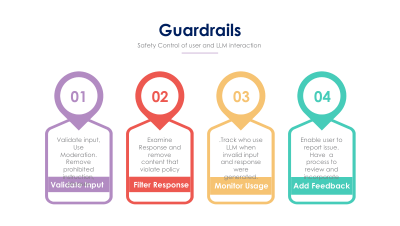
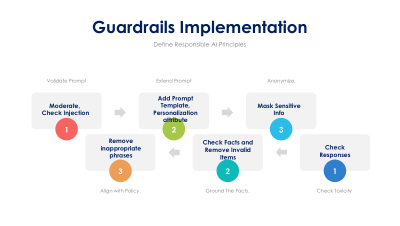
Generative AI is based on "comprehend existing" data and determine trajectories data can take. It uses it for generation.
Generative AI works by comprehending existing data, identifying patterns, and mapping the possible trajectories that data can take. It then leverages these insights to generate new content such as text, images, or solutions that aligns with the learned structures while exploring novel variations.
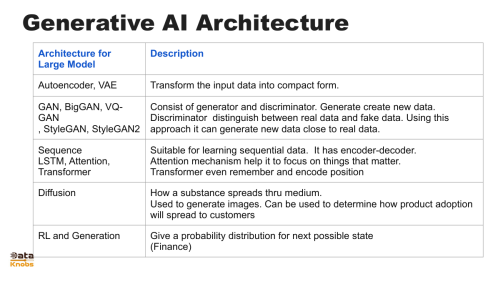
Diffusion architecture is suitable for generation
Transformer are suitable for language gentration in sequence
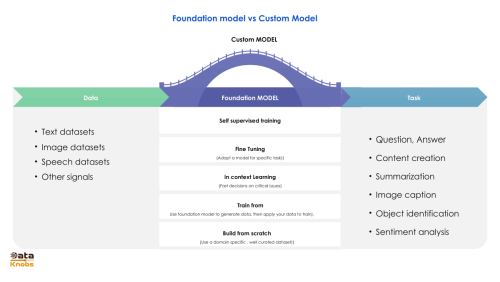
Generative AI (GenAI) models come in various architectures, each designed to handle specific types of tasks. The most widely used are Large Language Models (LLMs) based on the transformer architecture, which uses self-attention mechanisms to understand and generate human-like text. Transformers power models such as GPT, PaLM, and LLaMA, enabling them to capture long-range dependencies and context efficiently. Beyond text, multimodal architectures like CLIP and Flamingo combine language and vision, allowing models to interpret images alongside text. Diffusion models, such as Stable Diffusion and DALL·E, are another branch of GenAI that excel at image generation, gradually transforming noise into coherent visuals guided by textual prompts. Similarly, models like Whisper specialize in speech-to-text, leveraging sequence-to-sequence learning tuned for audio inputs.
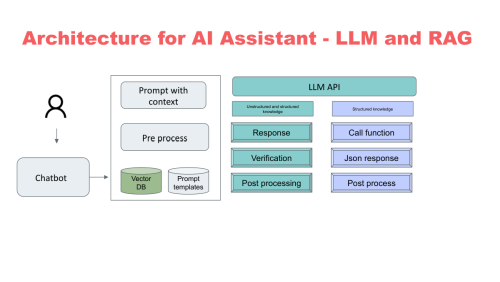
LLM architectures also vary by design goals and efficiency strategies. Decoder-only models (e.g., GPT-4, LLaMA) excel at generative tasks like writing, coding, and reasoning, while encoder-decoder models (e.g., T5, FLAN-T5) are particularly strong in translation, summarization, and instruction following. Some models use Mixture of Experts (MoE) architectures, like Google’s Switch Transformer, which activate only subsets of parameters during inference to balance scale with efficiency. Others explore retrieval-augmented generation (RAG), integrating external knowledge sources such as vector databases to extend a model’s effective memory. These variations reflect the broader trend of tailoring architectures to achieve better performance, efficiency, and adaptability across diverse generative AI applications.