crud-operations-in-vectr-db
Detail Article |
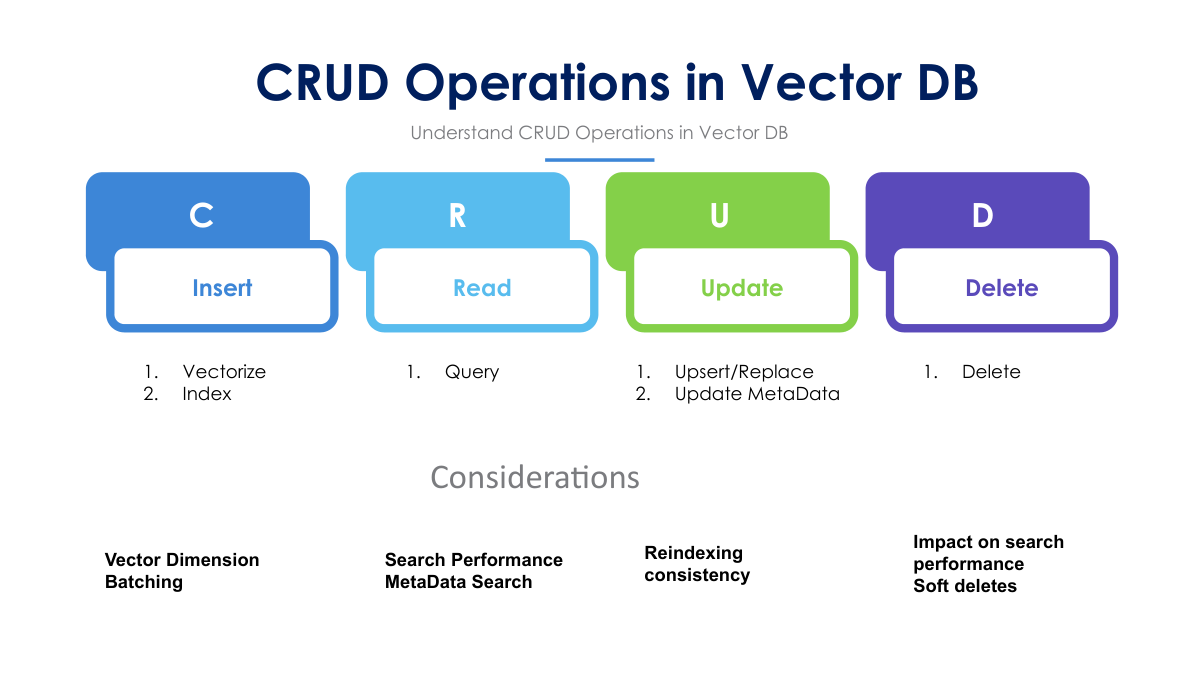
CRUD Operations in Vector Databases: Key Considerations and Design FactorsVector databases (Vector DBs) are optimized for storing and searching high-dimensional vectors, which makes them powerful for tasks like semantic search, recommendation systems, and retrieval-augmented generation (RAG). However, performing traditional CRUD (Create, Read, Update, Delete) operations on vector databases can be more complex compared to relational or NoSQL databases due to the nature of vector data and the need for efficient similarity searches. This article will guide you through how to perform CRUD operations on a vector database and highlight the considerations and design factors you need to account for, particularly if your system requires frequent updates. CRUD Operations in Vector Databases1. Create (Insert)Inserting data into a vector database typically involves two main steps:
Example code snippet (using Pinecone, a popular vector database service): Considerations:
2. Read (Query)Querying a vector database generally involves performing a nearest neighbor search. In vector DBs, the "read" operation typically looks for the top-k vectors that are closest (in terms of cosine similarity, Euclidean distance, or other metrics) to the query vector. Example: Considerations:
3. UpdateUpdating data in vector databases involves either:
In vector DBs, upserts (update or insert) are commonly used. If an ID already exists, the vector is updated. Otherwise, the vector is inserted as new data. Example: Considerations:
4. DeleteDeleting data in a vector database removes both the vector and any associated metadata. Example: Considerations:
Challenges and Considerations for Frequent Updates in Vector DBsPerforming frequent CRUD operations—particularly updates and deletes—on a vector database presents several unique challenges compared to traditional databases. Here are key considerations and design factors to keep in mind: 1. Indexing EfficiencyWhen frequent updates are required, re-indexing can become a bottleneck. Many vector databases use indexing algorithms like HNSW or IVF to accelerate search, but these can be computationally intensive to maintain. The following strategies can help:
2. Storage OverheadsVector databases store high-dimensional vectors, which can consume significant amounts of storage space, especially with frequent inserts and updates. To mitigate this:
3. Search Performance DegradationFrequent updates, especially if vectors are added or deleted frequently, can lead to "fragmentation" of the index, degrading search performance. To avoid this:
4. Consistency in Distributed SystemsIn distributed systems where vector DBs span multiple nodes, maintaining data consistency during CRUD operations is critical. Key strategies include:
5. Cost ImplicationsVector databases can be expensive to operate, particularly if they require frequent updates. High-dimensional vectors lead to increased storage costs, and search operations can be computationally intensive. When designing your system:
Design Factors for Optimizing CRUD Operations in Vector DBs
ConclusionCRUD operations in vector databases are fundamental for dynamic AI applications, but they come with unique challenges. Frequent updates and large-scale data management require careful consideration of indexing, storage, and performance optimization. For businesses and data scientists, the key to successful vector DB operations is balancing performance and scalability with cost efficiency and operational simplicity. |